1.1 PROTECCION
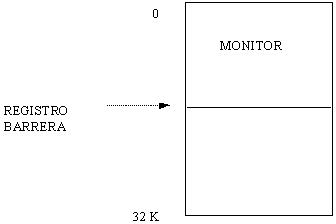
La memoria fisica de una computadora es comúnmente dividida en dos áreas, memoria del monitor residente y memoria del usuario. El problema principal de este esquema es el proporcionar una protección eficiente que evite que programas del usuario modifiquen (accidentalmente o intencionalmente) código o datos del monitor residente, ya que esto dejaría fuera de acción al sistema operativo. Existen varias soluciones a este problema, pero el mas común es el de utilizar un registro de límite de dirección comúnmente llamado "registro barrera" (fence register), en el cual se coloca la dirección de la primera posición de memoria que un programa del usuario puede utilizar. Esto se ilustra en la siguiente figura.
El monitor puede ser cargado en la parte baja de la memoria o en la alta; sin embargo, es común cargarlo en la baja. En este esquema, cada dirección generada por una instrucción o dato de un programa, es comparada con el contenido del registro barrera. Si la dirección generada es mayor o igual que la barrera, entonces la dirección es válida ya que comprende alguna localidad de la memoria del usuario. En caso contrario, se trata de una referencia ilegal, por lo que se genera una interrupción al S.O. para que maneje este tipo de error (generalmente imprime un letrero y aborta el programa).

La dirección del registro de barrera puede ser cambiado según las necesidades de memoria, por ejemplo si crece el monitor residente al actualizarlo. Otro problema a considerar es la carga en memoria de los programas del usuario. Aunque la dirección de la memoria de la computadora empieza en 00000, la primera dirección del programa del usuario no puede ser 00000, sino la primera dirección más allá de la barrera. Una de las formas de corregir esto es al tiempo de compilación, ya que si se conoce la dirección de la barrera, se pueden generar direcciones absolutas que comiencen y se extiendan a partir de la barrera. Sin embargo, si la dirección de la barrera cambia, es necesario recompilar el programa para poder ser corrido nuevamente.
1.2 RELOCALIZACION
Una mejor alternativa al método de direcciones absolutas, consiste en generar direcciones relativas o relocalizables, las cuales no toman en cuenta el valor de la barrera al momento de compilación, sino que la corrección es diferida hasta el tiempo de carga o de ejecución del programa. En el primer método, al momento de cargar el programa en memoria, el valor de la barrera es sumado a todas las direcciones en que debería cargarse cada instrucción o dato del programa, así como también a las direcciones a las que hace referencia cada instrucción (variables del programa), de tal forma que siempre se tengan direcciones a partir de la barrera. Este método funciona siempre y cuando la barrera no cambie durante la ejecución del programa, sino solamente antes de correr el programa (p.e. entre programa y programa). Debido a esta condición de barrera estática, se dice que se tiene "Relocalización Estática". En muchos casos, los sistemas operativos cuentan con partes transitorias que se pueden eliminar y volver a cargar. Por ejemplo, en los casos en que algún manejador de dispositivo no se utilice frecuentemente, puede ser quitado para utilizar ese espacio de memoria para programas del usuario, y volver a cargarlo cuando sea requerido por algún programa en ejecución. Este esquema, hace que sea necesario cambiar la dirección de la barrera incluso durante la ejecución de un programa. Una solución a este problema es cargar el programa en memoria igual que en el método anterior, sumándole el valor de la barrera a todas las direcciones generadas por el compilador, excepto a las direcciones a que hacen referencia las instrucciones del programa (variables); éstas son dejadas tal cual. La corrección es hecha hasta el momento en que al ser ejecuta cada instrucción en el CPU, se genere un intento de accesar la memoria. En ese momento, a la dirección generada le es sumado el valor de la barrera y luego es enviada a la memoria. Por lo tanto, el usuario siempre trabaja con direcciones lógicas (las generadas por el compilador), y el hardware de relocalización se encarga de generar direcciones físicas. Por ejemplo si la barrera se encuentra en 1700, cualquier intento de accesar la localidad 0000, será automáticamente relocalizada a 1700. Un acceso a la localidad 515, será relocalizada a la 2215. A este sistema se le llama relocalización dinámica ya que la barrera puede ser cambiada en cualquier momento. El esquema del hardware utilizado es el siguiente.
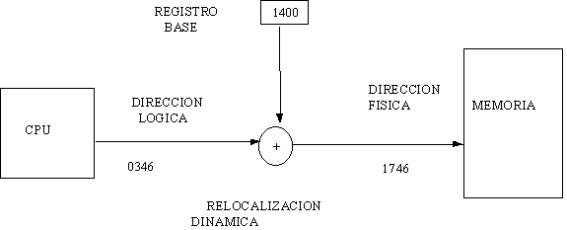
En este sistema, el registro barrera es ahora
llamado registro base.
Por lo tanto, si es necesario cambiar la barrera,
solo es necesario cambiar el contenido del registro base, y trasladar el
programa del usuario a las nuevas localidades de memoria relativas a la nueva
barrera, y continuar con la ejecución del programa.
Los sistemas anteriormente vistos, funcionan bien
para sistemas operativos uniprogramados; sin embargo, si cargamos más de un
programa en el área del usuario, ya no proporcionan la protección debida,
ya que si bien el S. O. queda protegido, los programas de los usuarios no.
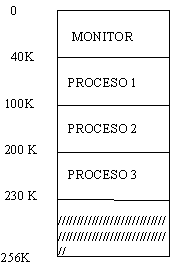
Considere el siguiente esquema.
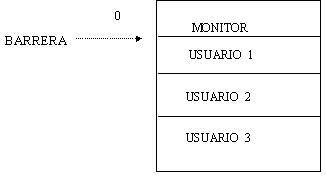
Si ejecutamos el programa del usuario1, es posible
que éste pueda modificar el código o los datos de los programa 2 y 3. Si
movemos la barrera hasta el inicio del programa 2, el programa 1 queda
protegido al igual que el monitor; sin embargo, el programa 3 queda aún
desprotegido.
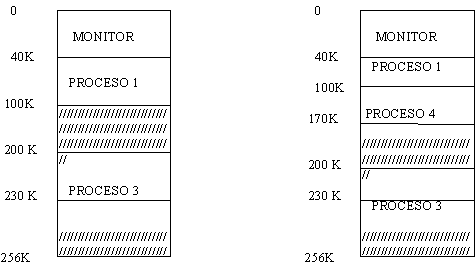
Una
solución a este problema, es utilizar dos registros para delimitar
plenamente la memoria del programa en ejecución. Esto se ilustra en las
siguientes figuras.
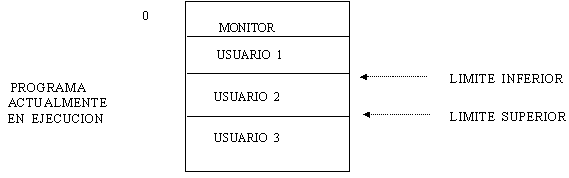
Los límites
se implementan con
registros igual que anteriormente. De esta manera, si el programa en
ejecución es el 2, el monitor y el programa 1 quedan protegidos por el límite
inferior, mientras que el programa 3 queda protegido por el límite
superior. Una vez finalizada la ejecución del programa 1, los registros son
movidos al programa 2, y así sucesivamente .
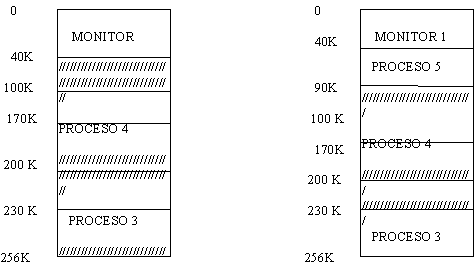
Este esquema de cambio de barreras obviamente requiere
un sistema de relocalización dinámica. El hardware utilizado para tal
efecto es el siguiente.
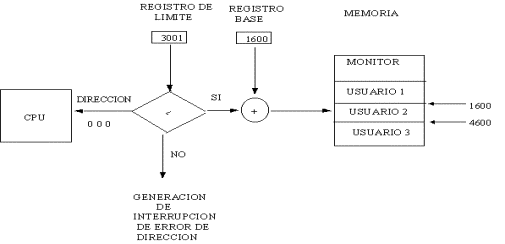
El registro de límite checa por el límite
superior que puede generar un programa antes de ser relocalizado dinámicamente
por el registro base mientras que el límite inferior queda definido por la
dirección 0000 que generan los compiladores.
Así
por, ejemplo en la figura de arriba tenemos como límites 0000 + 1600 = 1600
como límite inferior, y 3000 + 1600 = 4600 como límite superior. Todas las
direcciones generadas por el programa del usuario 2 deben de estar en ese
rango o se generará un error.
El uso
del esquema anterior u otros similares permiten tener más de un usuario
residente en memoria simultáneamente, ya que es posible dividir la memoria en múltiples regiones llamadas particiones.
Dos
posibles métodos se derivan de este esquema:
Múltiples particiones contiguas fijas
Múltiples
1.3
MULTIPLES PARTICIONES CONTIGUAS FIJAS
En
esta opción, se seleccionan regiones fijas de memoria para crear procesos,
por ejemplo una región de 10 K bytes para procesos muy pequeńos, regiones
de 20 K para procesos de tamańo promedio, y 50 K para procesos grandes.
Cuando
un proceso llega del exterior, es puesto en la cola de procesos o spool
manejada por el asignador de procesos, cuando le toca su turno (generalmente
en forma PEPS), la cantidad de memoria que requiere es tomada en cuenta y es
comparada contra las regiones de memoria vacías; si el proceso puede ser
cargado en alguna de ellas lo hace, pero si no, entonces busca el siguiente
que pueda ser cargado en las regiones disponibles. Para saber que regiones
de memoria están disponibles, se implementa una lista llamada "cola de
regiones de memoria disponibles", en la cual se anota la cantidad de
memoria del hueco libre y la dirección donde inicia.
El
asignador de procesos también busca optimizar el desperdicio de memoria; es
decir, no cargar programas muy pequeńos en regiones muy grandes ya que éstas
son fijas. A este desperdicio se le llama fragmentación interna.
Esto se ilustra en la figura.
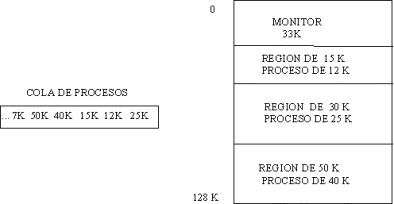
Como puede verse, el primer proceso
puede ser cargado en la región de 30K con una fragmentación de 5K, el de
12K en la de 15K con fragmentación de 3, el de 15K tendrá que esperar a
que se desocupe la región de 15K (o decidir cargarla en la de 40K con gran
fragmentación), la de 40K puede ser cargada en la de 50K con un desperdicio
de 10K, y las de 50K y 7K tendrán que esperar a que alguna región adecuada
se desocupe.
También es posible formar varias colas de
procesos, una para cada región de memoria (en este caso 3). Esto se ilustra
en la siguiente figura.
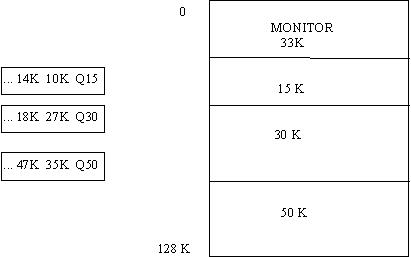
Entonces se tienen 3 asignadores de procesos
independientes. Cada uno verifica en la cola de regiones de memoria
disponibles sí su hueco está libre, y procede a cargar procesos en caso
afirmativo.
El problema principal de este sistema es cómo
seleccionar los tamańos de las regiones y cuántas de ellas se tendrán,
tal que se tenga la menor fragmentación interna posible.
Por lo tanto, el máximo grado de multiprogramación
es limitado por el número de regiones que se escojan.
También si se escogen demasiadas regiones, éstas
tenderán que ser pequeńas, por lo que se puede sufrir de un problema peor
que es la fragmentación externa. Esta se tiene cuando existen regiones de
memoria disponibles pero son muy pequeńas para cargar un proceso, por lo
que se tendrá que esperar por otro hueco más grande.
1.4
MULTIPLES PARTICIONES CONTIGUAS VARIABLES
El problema con particiones fijas es determinar los
mejores tamańos de regiones para minimizar la fragmentación interna y
externa.
Sin embargo, con un conjunto de procesos dinámicos,
es poco probable llegar a una condición óptima. La solución a este
problema es permitir que las regiones varíen de tamańo dinámicamente.
Esta
solución es llamada múltiples particiones contiguas variables.
Esta forma de manejo de memoria consiste en tener una cola de regiones de memoria que están disponibles. Al inicio se tiene un solo bloque de memoria para programas del usuario que resulta de cargar el Sistema Operativo en la memoria disponible. Esto se ilustra en la figura con una memoria de 256K.
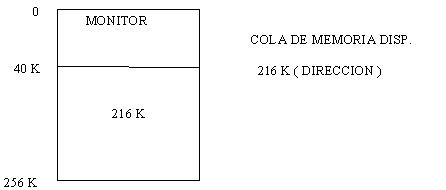
Cuando los procesos llegan, se checa en la cola de
regiones de memoria disponibles si se puede cargar el proceso. Si la región
es muy grande, solo se asigna la necesaria y el resto es puesto en la cola
de regiones de memoria disponibles.
Por
ejemplo asuma que los siguientes procesos requieren servicio:
No.
de Proceso Memoria requerida Tiempo ráfaga
1
60 K
10
2
100 K
5
3
30 K
20
4
70 K
8
5
50 K
15
Si el
algoritmo usado es del tipo primero en llegar primero en salir, podemos
cargar a memoria los 3 primeros procesos:
La cola de regiones de memoria disponibles queda:
26, 30 con sus respectivas direcciones de inicio. Como el proceso 5 no se
puede cargar, nos deja una fragmentación externa de 56K. El siguiente en terminar es el proceso 1, permitiéndonos
cargar el proceso 5 en el área de 60K dejado por el proceso 1, y poniendo
en la cola de regiones de memoria disponibles el área no usada (10K).
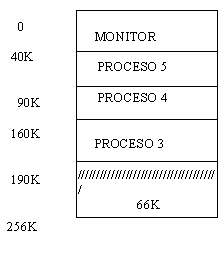
La cola de regiones de memoria nos queda: 26, 30, 10 con sus respectivas direcciones.
Como ya no hay procesos que cargar, no podemos
afirmar que se tenga una fragmentación externa de 66K. Esto dependerá de
que se pueda cargar o no el siguiente proceso que llegue. En caso negativo,
entonces se tiene efectivamente una fragmentación externa de 66K.
El esquema anterior, requiere de una estrategia
para asignar los huecos de memoria disponibles. En general se tienen 3
algoritmos: "primero en ajustar" (first-fit), el "mejor en
ajustar" (best-fit), y el "peor en ajustar" (worst-fit).
"PRIMERO
EN AJUSTAR" (First Fit). Carga el programa en el primer hueco
suficientemente grande que encuentra en la lista de regiones de memoria
disponibles. Es el algoritmo más rápido.
"MEJOR
EN AJUSTAR" (Best Fit). Busca por el hueco de memoria que menos
fragmentación produzca. Si la lista de regiones de memoria disponibles es
mantenida en orden ascendente, es fácil y rápido encontrar la más
adecuada. De otra manera debemos buscar toda la lista.
"PEOR
EN AJUSTAR" (Wosrt Fit). Carga el programa en el hueco más grande que
encuentra y deja en la lista de regiones disponibles el tamańo del resto de
la memoria no usada. Esta estrategia a veces rinde mejores resultados que la
de mejor en caber, ya que produce huecos grandes de fragmentación que
pueden ser mejor utilizados que fragmentaciones muy pequeńas.
Es
adecuado mantener la lista ordenada de mayor a menor para reducir el tiempo
de búsqueda.
El hardware usado para este sistema es exactamente
el mismo; es decir, dos registros que delimitan perfectamente el área del
programa a ejecutar.
COMPACTACION.
En la
última figura, se puede apreciar que existe una fragmentación de 66K
compuesta por 3 huecos de 10, 30 y 26K, los cuales son más difíciles de
usar que si fueran un solo bloque de 66K.
Sin embargo, es posible compactar la memoria haciendo que todos los
huecos disponibles se junten ya sea en la parte de abajo o del medio de la
memoria.
Esto se ilustra en la siguiente figura:
Para efectuar la compactación, es necesario
cambiar de localidad los procesos,
por lo que este sistema solo es posible si el hardware cuenta con
relocalización dinámica; ya que de otra forma, los
procesos no podrían
trabajar en sus nuevas
direcciones.
1.5
PAGINACION
El sistema de particiones variables sufre del
problema de fragmentación externa ya que un proceso debe ser cargado en
memoria contigua.
Este problema puede ser resuelto por compactación
o por paginación.
Paginación permite que un programa sea cargado en
memoria no contigua; es decir, en varios fragmentos fijos no contiguos.
El hardware utilizado en paginación se ilustra en
la siguiente figura.
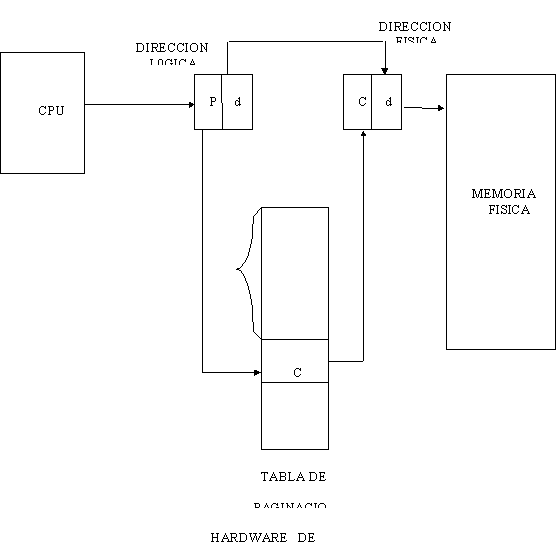
Cada dirección lógica generada por un programa en
el CPU, es dividida en dos
partes: un número de página (p) y un desplazamiento de página (d).
El número de página es usado como índice de la
tabla de páginas donde se encuentra la dirección del cuadro que le
corresponde en la memoria física.
Esa dirección es combinada con el desplazamiento
de página para definir la dirección exacta que se anda buscando. La
combinación es como sigue:
Dirección física = (no. de cuadro x no. de
palabras por página + desplazamiento de página)
Por
ejemplo, considere una memoria usando un tamańo de página de 4 palabras y
una memoria física de 28 palabras (7 cuadros). En la siguiente figura se
muestra cómo la memoria desde el punto de vista del usuario es mapeada en
memoria física.
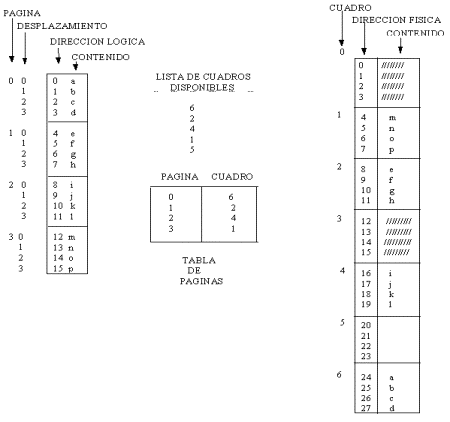
Por ejemplo, la dirección lógica 4 está en
página 1 y un desplazamiento de 0. De acuerdo a la tabla de páginas ésta
es mapeada en el cuadro 2, y la dirección exacta de la dirección lógica 4
es : (2 * 4 + 0)= 8.
La dirección lógica 13 corresponde a (1 * 4
+ 1)= 5
La
dirección lógica 3 corresponde a (6 * 4 + 3)=27
La
dirección lógica 0 corresponde a (6 * 4 + 0)=24
Es
importante notar que paginación es por sí misma una forma de relocalización
dinámica.
Un
aspecto importante de paginación es la clara separación entre la memoria
desde el punto de vista del usuario y la memoria física actual. El usuario
ve la memoria como un espacio contiguo, conteniendo solo su programa. En
realidad, el programa del usuario esta disperso a través de toda la memoria
física, la cual también contiene otros programas. La traducción entre
ambas memorias es realizada por la tabla de páginas que es manejada por el
sistema operativo.
Paginación
viene a ser un esquema de múltiples particiones fijas no contiguas.
ASIGNACION
DE MEMORIA EN PAGINACION.
En el
sistema de paginación, cuando un proceso nuevo llega al dispositivo de
spool, es seleccionado por el asignador de procesos para ser cargado a
memoria.
Primero
comprueba su requerimiento de memoria en páginas.
En seguida busca en la lista de cuadros de memoria
disponibles para ver si es posible cargar el proceso. Cada página requiere
un cuadro, por lo que si el proceso consta de n páginas, deberá haber n
cuadros de la memoria física para poder cargarlo. Esto se ilustra en la
figura anterior.
El sistema de paginación está exento de
fragmentación externa, ya que todos los cuadros pueden ser otorgados a
cualquier proceso que lo necesite.
Sin embargo, es posible tener fragmentación
interna ya que los cuadros son de tamańo fijo y sí un programa no logra
llenar la página completa, se tendrá un desperdicio. El peor caso es
cuando un programa requiere de n páginas más una palabra, ya que casi toda
la página quedará vacía.
PAGINAS
COMPARTIDAS.
Una de las ventajas de paginación, es poder
compartir código común. Esta característica es particularmente importante en
sistemas operativos det tiempo compartido.
Considere un sistema el cual soporta 40 usuarios,
cada uno de los cuales ejecuta un intérprete BASIC. Si el intérprete
consiste de 60K de código y 40K de espacio para el programa y datos del
usuario, se requerirían 40 x 100= 4000K para soportar a los 40 usuarios.
Si el código es reentrante (no modificable a sí
mismo), éste puede ser compartido por todos los usuarios, por lo que sólo
se requeriría una copia del intérprete (60K) para todos, más 40K de código
de datos para cada uno de los procesos. Esto nos da un requerimiento de 60K
+ 40(40k) = 1660K, un ahorro considerable frente a los 4000K.
En la
siguiente figura se ilustra un ejemplo similar con un intérprete BASIC de 3
páginas compartido por 3 procesos.
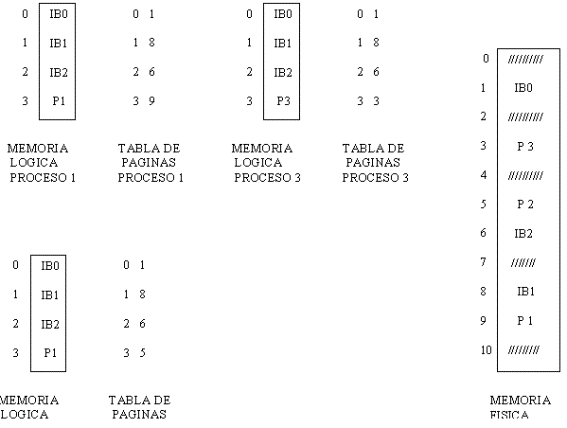
COMPARTIMIENTO DE CODIGO EN AMBIENTE DE PAGINACION
1.6
SEGMENTACION
Segmentación es otro método de administración de
memoria, el cual permite cargar un programa en memoria no contigua.
Este método
es más natural ya que generalmente un programa está constituido por un
programa principal y varios subprogramas separados, por lo que cada una de
estas entidades puede ser guardada en un segmento de memoria individual de
tamańo exacto según lo requiera cada uno.
Lo anterior indica que los segmentos deben de ser
de longitud variable, en contraste con paginación en donde las páginas son
de longitud fija.
Cada segmento tiene un nombre o número y una
longitud. El usuario por esto especifica cada dirección por dos cantidades:
un nombre de segmento y un desplazamiento.
Dado que ahora una dirección dentro de un programa
del usuario (dirección lógica), debe especificarse como una dirección de
2 dimensiones, y dado que la memoria física es aún un arreglo de una sola
dimensión, es necesario implementar un dispositivo que mapee o convierta
una dirección de dos dimensiones en otra de una sola dimensión. Esto se
hace por medio de la tabla de segmentos.
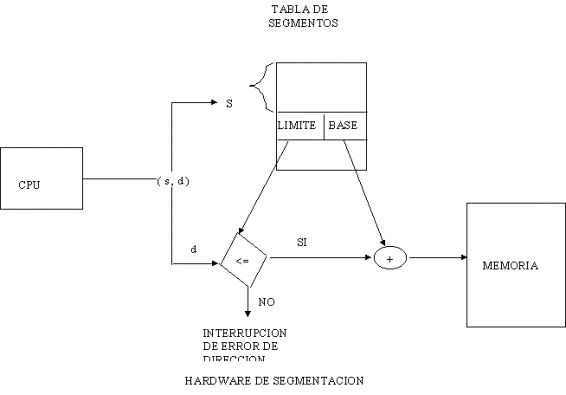
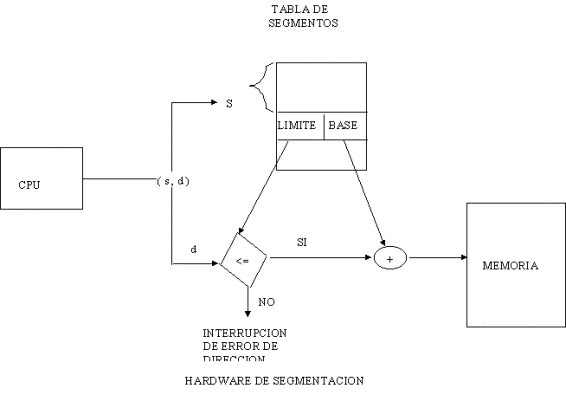
HARDWARE DE SEGMENTACION
El uso
de la tabla de segmentos es ilustrada en la figura anterior.
Una
dirección lógica consiste de dos partes: un número de segmento
"s" y un desplazamiento "d" dentro del segmento. El número
de segmento es usado como índice en la tabla de segmentos.
El renglón apuntado por ese índice, tiene la
dirección donde empieza el segmento (llamada base del segmento), y un límite
que indica el número de palabras de que consta ese segmento. El
desplazamiento "d" de la dirección lógica, debe estar entre 0 y
el límite del segmento: sí no, entonces se tiene un error de dirección,
por lo que se manda una interrupción al sistema operativo.
Si el desplazamiento es legal, entonces es sumado a
la base del segmento, para producir la dirección de la palabra deseada en
la memoria física. Considere el ejemplo mostrado en la siguiente figura:
Por lo tanto, una referencia a la palabra 53 del
segmento 2 es mapeada en la localidad 4300 + 53 = 4353.
Una referencia a la palabra 1222 del segmento cero
resultaría en un error y por lo tanto interrupción al sistema operativo,
ya que el desplazamiento 1222 excede el límite del segmento cero que es de
1000.
FRAGMENTACION
EN PAGINACION.
El
asignador de procesos debe encontrar y cargar en memoria todos los segmentos
de un programa del usuario. Esta situación es similar a paginación excepto
que los segmentos son de longitud variable, (las páginas son todas del
mismo tamańo), por lo que la fragmentación interna puede ser despreciable.
Sin embargo, se puede tener fragmentación externa cuando todos los
segmentos disponibles son demasiado pequeńos para cargar cierto programa.
Segmentación viene a ser un esquema de múltiples
particiones no contiguas variables.
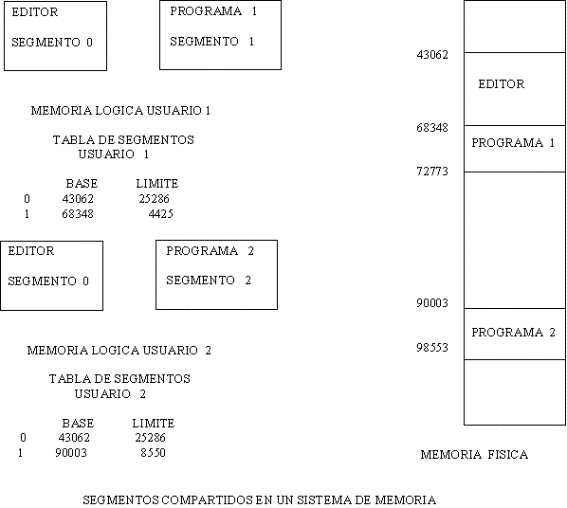
SEGMENTOS COMPARTIDOS
Una ventaja de segmentación es que pueden
compartirse segmentos de código común
a varios procesos: por ejemplo compartir entre dos usuarios una subrutina
escrita en FORTRAN, o un editor de textos. Esto se ilustra en la siguiente
figura:
Regresar al menú principal
