
5.1
CONCEPTO DE ARCHIVO
Para facilidad de uso de un sistema de cómputo, los
sistemas operativos proporcionan un medio abstracto que permite manejar los
dispositivos de almacenamiento del sistema, sin necesidad de conocer las propiedades
físicas de éstos. Esto se hace mediante la definición de una unidad de almacenamiento
lógico en lugar de una unidad de almacenamiento físico.
Esta unidad de almacenamiento lógico es el archivo.
Un archivo es una colección de información relacionada
definida por su creador. Regularmente los archivos representan programas y/o
datos.
En general un archivo es una secuencia de registros
lógicos.
Los registros lógicos están constituidos por bytes
o grupos de bytes que pueden significar para el usuario diferentes tipos de
datos (por ejemplo valores numéricos o cadenas de caracteres).
Los registros lógicos pueden ser definidos de varios
tamańos de anchura: sin embargo, si ésta no es la misma que la del registro
físico (disco), crea el problema de desperdicio de espacio si es menor, o de
no poder escribirlo si es mayor.
Este problema es solucionado en el S.O. mediante
el uso del factor de bloqueo.
En este método, los registros lógicos son agrupados
o empacados según su tamańo para luego ser almacenados en el registro físico.
Por ejemplo: Si la anchura del registro físico es
de 256 bytes, y el registro lógico
fue definido de 128 bytes, entonces tendremos un agrupamiento de dos registros
lógicos por cada registro físico.
Se dice que se tiene un factor de bloqueo de dos.
Si el registro lógico se define de 80 bytes y el registro físico es de 256 bytes, el S.O. adopta un factor de bloqueo de 3.
Sin embargo en este tamańo de registro lógico se
desperdicia algo de espacio.

También se puede dar el caso de que el registro lógico
exceda en tamańo al registro físico. En este caso, un registro lógico es colocado
en más de un registro físico. Por ejemplo si un registro lógico es de 500 bytes
y el físico de 256, nos queda:
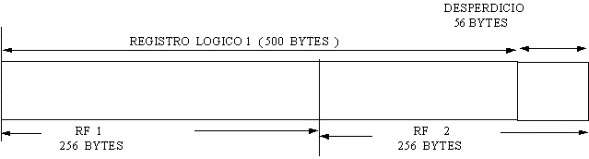
En la mayoría de los S.O., el usuario puede escoger
el factor de bloqueo que considere más adecuado.
El registro físico no puede ser modificado dado que
es una característica física de la unidad de disco.
El S.O. también provee la facilidad de tener registros
de longitud variable, aunque esto es más común en cintas que en discos.
Las cintas, dadas
sus características físicas
que solo permiten acceso secuencial, son
utilizadas solo para respaldos de información.
5.2
OPERACIONES DE ARCHIVOS
Es deseable que un S.O. permita crear archivos, escribir
en ellos, leerlos y eliminarlos cuando no se necesiten más.
También es deseable poder editar y modificar un archivo, copiarlo a otro
dispositivo por ejemplo a la impresora, y
5.3
TIPOS DE ACCESO
SECUENCIAL
Los registros lógicos se escriben uno detrás de otro por medio de un apuntador que se mueve automáticamente. El usuario no tiene control sobre el apuntador. Es difícil insertar una componente en medio de otras; así como eliminar una componente dada. Su uso de espacio es eficiente.
DIRECTO
Se puede especificar en
qué registro posicionar
el apuntador y escribir o leer en él.
Si no se tiene cuidado se puede desperdiciar mucho espacio.
5.4 ACHIVOS CON LLAVES DE BUSQUEDA
Auque el acceso directo es el más rápido, si no se
sabe en que registro está la información que buscamos no es posible llegar a
ella. Para poder hacer una buena organización y acceso rápido a la información
se utilizan los archivo con llaves de búsqueda. A continuación se revisan varias
técnicas.
·
Archivos
con índices. Constan de un archivo de datos y uno o más archivos de índices.
o
Indexado
puro (no secuencial). Desarrollado con índices densos
(un apuntador por cada registro del archivo de datos). El archivo de
datos se mantiene en orden cronológico (como se dio de alta), mientras que el
de índices se mantiene ordenado por la llave de búsqueda. Se pueden tener varias
llaves de búsqueda alternas. Ocupa más espacio y es más lento que el indexado
secuencial. Es fácil agregar nuevos registros, pero se requiere reordenar el
archivo de índices cada vez que se haga ésto.
o
Indexado
secuencial. Desarrollado generalmente
con índices escasos (aunque también pueden desarrollarse con índices densos).
El archivo de datos se ordena físicamente
de acuerdo a la llave de búsqueda y después se generan los archivos de
índices. En el nivel de índices más alto se hace una búsqueda binaria que nos
posiciona en otro nivel, y así sucesivamente hasta llevarnos al archivo de datos;
una vez ahí, se busca secuencialmente ya que el archivo está ordenado físicamente.
No se pueden tener llaves de búsqueda alternas. Si se necesita insertar nuevos
registros se generan áreas de desborde (listas encadenadas). Ocupa menor espacio
en disco y tiene un tiempo de acceso más rápido que los indexados puros. Se
recomienda para mantener grandes volúmenes de información que no cambia con
mucha frecuencia y que requiere tiempos de acceso rápidos.
o
Árboles.
Se basan en la versatilidad que proporciona el tener
índices que se expanden o encogen dinámicamente. El archivo de datos
se mantiene en forma cronológica. Sus algoritmos para buscar, insertar y eliminar
registros son más complejos que los de ambos tipos de indexados, pero tienen
la ventaja sobre éstos que sus archivos casi no necesitan ser reorganizados.
Existen varios tipos de archivos con árboles, como los Search Trees ,
los Balanceados B y B+, los Binarios Balanceados (AVL), y Binarios No-balanceados.
Los más usados son los B y B+.
§
Árboles
B+. Cualquier camino desde la raíz a una hoja tiene la misma longitud. Permiten
tener llaves de búsqueda repetidas (por ejemplo, varios nombres homónimos).
Impone un gasto extra durante la inserción o eliminación de nodos, además de
requerir espacio extra. Su estructura es más sencilla que los B. Usa varios
niveles de índices: los internos y los de hoja. El apuntador al archivo de datos
se almacena siempre en los nodos hoja.
§
Árboles
B. Similares a los B+ pero elimina el almacenamiento de valores de llave de
búsqueda repetidos, por lo que requiere menos nodos para almacenar los índices.
Su estructura es más compleja debido a que sus ramas son más largas y por lo
tanto la eliminación de un nodo resulta más complicada que en un B+.
Su acceso es ligeramente más rápido que los B+. Usa varios niveles de
índices: los internos y los de hoja. El apuntador al archivo de datos se puede
almacenar en cualquier nivel. Puede requerir más niveles que los B+.
·
Hashing.
Utiliza funciones que convierten las llaves de búsqueda a números enteros entre
0 y el número máximo de entradas en el archivo de datos. No existen archivos
de índices; por esta razón, este método es el más rápido. Sin embargo, tiene
el problema de que dos o más llaves pueden generar el mismo número de registro
ocasionando colisiones. También tiene el problema de que si el archivo alcanza
el número máximo de entradas ya no pueden insertarse nuevos registros. Existen
varios métodos para manejar colisiones.
o
Memoria
abierta. Si al tratar de insertar un nuevo registro, su llave genera una colisión,
el registro se coloca en la posición más cercana al lugar que le correspondía.
Por lo tanto, cuando una llave nos lleva a un registro en el archivo de datos
y éste no es el que buscamos, se hace una búsqueda secuencial hasta
encontrar el registro deseado.
o
Encadenamiento
de colisiones. Se genera una lista encadenada por cada registro que genera colisiones.
Cuando se llega a un registro y éste no es el que buscamos, entonces realizamos
una búsqueda secuencial en la lista
encadenada hasta encontrar el registro deseado.
o
Doble
hashing. Cuando una llave genera una colisión, se pasa por una segunda función
de hashing (diferente a la primera), dando oportunidad de que la posibilidad
de generar una colisión disminuya. Si aún así colisiona, se usa cualquiera de
los otros dos métodos.
5.5
DIRECTORIOS
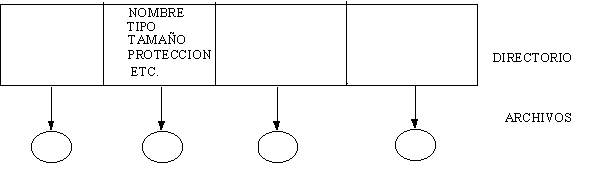
Cada dispositivo de almacenamiento, mantiene una
tabla de contenido, en la cual se especifica el nombre, dirección y tamańo de
cada uno de los archivos existentes en esa unidad. Esta tabla es conocida como
directorio.
La información contenida en un directorio es comúnmente
la siguiente:
·
Nombre de archivo.
·
Tipo de archivo (por ejemplo binario o ASCII).
·
Localización, dispositivo y dirección donde se encuentra
el archivo.
·
Tamańo en bytes, palabras o bloques.
·
Máximo tamańo disponible.
·
Protección de acceso para lectura, escritura,
ejecución, etc.
·
Fecha de creación o última modificación.
·
Otros.
ESTRUCTURA DE UN DIRECTORIO
Existen muchas formas y métodos de implementar un
directorio. Algunas de las más comunes son las siguientes.
DIRECTORIO DE UN NIVEL
Es el más simple de todos. En este tipo de directorio
se agrupan todos los archivos del sistema en una sola lista o tabla, por lo
que si se tiene más de un usuario, es necesario que los nombres sean únicos.
Es recomendable para sistemas de un solo usuario. Se puede implementar en forma
lineal o con "hashing".
DIRECTORIO LINEAL.
Está constituido por una lista lineal encadenada.
Es fácil de implementar pero es lenta en acceso ya que para saber si un archivo
existe en el directorio hay que hacer una búsqueda secuencial. Sin embargo,
si la lista se ordena alfabéticamente, es posible ejecutar búsquedas binarias
que reducen notablemente el tiempo de búsqueda. La desventaja es que al dar
de alta o de baja nuevos archivos, es necesario reordenar la lista.
DIRECTORIO CON TABLA HASH.
Este tipo de algoritmo mejora notablemente el tiempo
de búsqueda y tanto las inserciones como las eliminaciones son muy directas.
Este algoritmo convierte los nombres de archivos
a números enteros entre cero y el máximo tamańo asignado a la tabla Hash. Por
ejemplo una tabla de 256 registros, generará números entre 0 y 255. Obviamente
si la tabla se llena, no se podrá agregar otro más ya que habría que modificar
el algoritmo.
Además un directorio con tabla Hash debe proveer
un sistema de manejo de colisiones ya que dos o más archivos con nombres similares
pueden producir el mismo número de registro.
DIRECTORIO DE DOS NIVELES
La principal desventaja de un directorio de un solo
nivel, es la confusión de nombres de archivos entre diferentes usuarios.
La solución es crear un directorio propio para cada usuario. Esto se hace por medio de un árbol de dos niveles como se ilustra en la siguiente figura.
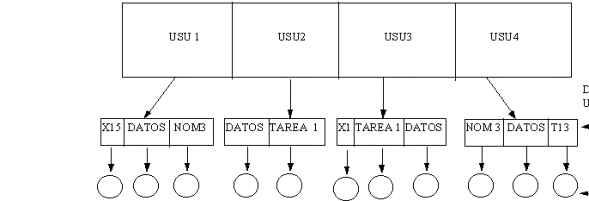
En este tipo de sistema, cuando un usuario se da
de alta, el directorio maestro es buscado hasta encontrar el directorio del
usuario correspondiente (generalmente a través de un número de cuenta). Cuando
ese usuario lista el directorio, sólo los archivos contenidos en su directorio
son mostrados. Esto permite tener nombres repetidos en otros directorios de
otros usuarios, sin peligro de borrar o modificar el archivo equivocado, ya
que cada usuario solo tiene acceso a los archivos de su propio directorio.
Esto último puede representar un problema cuando
dos o más usuarios requieren trabajar en equipo y compartir archivos.
Esto se puede solucionar permitiendo que los usuarios
tengan la capacidad de compartir algunos archivos. Por ejemplo, colocar los
archivos más comúnmente usados (editores, compiladores, etc.) en un directorio
público al cual se puede tener un acceso limitado.
DIRECTORIOS DE MULTIPLES NIVELES. (Estructura de
árbol)
Cuando un usuario tiene diferentes aplicaciones en
un mismo directorio, por ejemplo, programas de COBOL, BASIC y PASCAL, es deseable
poder tener cada grupo de programas en directorios separados, pero bajo el control
del mismo usuario.
Esto se logra por medio de la creación de subdirectorios
o directorios de múltiples niveles. Ejemplo:
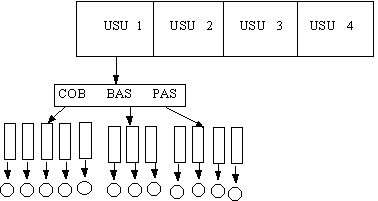
El S.O. MSDOS, permite al usuario organizar su directorio
en forma de árbol, por ejemplo como el del usuario 1 de la figura anterior.
El S.O. Unix usa una estructura de árbol. El árbol
tiene una raíz. Cada archivo tiene un nombre de trayectoria único. Un nombre
de trayectoria, es el camino desde la raíz hasta el archivo pasando a través
de los subdirectorios.
DIRECTORIO DE GRAFOS ACICLICOS
Son una generalización de los directorios del tipo
de árbol.
Un directorio de árbol generalmente prohibe el compartir
archivos o directorios. Un grafo acíclico sí permite compartir tanto archivos
como subdirectorios completos. Esto se ilustra en la siguiente figura.
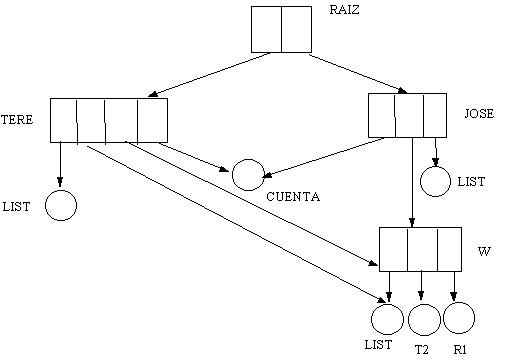
Note que no se generan ciclos de retorno a través de los mismos archivos y subdirectorios; de ahí su nombre acíclico.
Este tipo de directorios es recomendable en situaciones
en que un grupo de usuarios trabajan como equipo. En este caso, todos los archivos
a compartir se colocan en un directorio.
Los directorios individuales de cada miembro del
equipo, contendrán el directorio de
archivos a compartir como un subdirectorio del suyo, por lo que cada uno puede
listarlos y utilizarlos.
La búsqueda y eliminación de archivos es complicada
debido a que puede existir más de una trayectoria a un mismo archivo, cosa que
no sucede en los directorios de árboles (múltiples niveles).
DIRECTORIO DE GRAFO GENERAL
El directorio de grafo general permite una flexibilidad
total para compartir archivos al permitir que haya trayectorias cíclicas a través
de todo el directorio. Esto se ilustra en la siguiente figura.
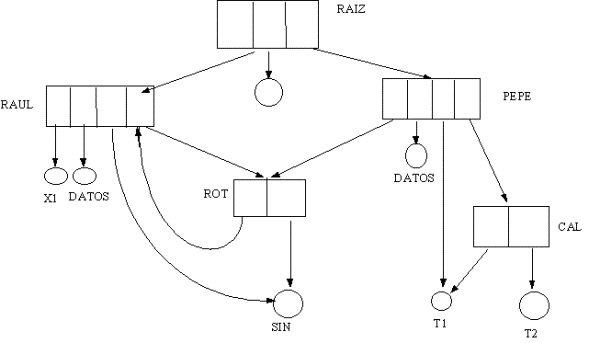
Dado que es permitido tener trayectorias cíclicas,
se puede caer en el problema de pasar por la misma trayectoria más de una vez
al buscar un archivo, o incluso caer en un lazo infinito. Por lo anterior,
se requieren algoritmos muy complicados para mantener este tipo de directorios.
5.6
PROTECCION DE ARCHIVOS
La necesidad de proteger los archivos es un resultado
directo de la habilidad de compartir archivos. En un sistema que no permite
compartir archivos, no es necesario un mecanismo de protección.
Los mecanismos de protección permiten compartir archivos
en una forma controlada, limitando el tipo de acceso que se puede tener a un
archivo.
Los tipos de acceso son los siguientes:
·
Lectura de
un archivo.
·
Escritura
o reescritura de un archivo.
·
Carga en memoria
de un archivo y ejecución.
·
Agregar nueva
información al final del archivo.
·
Eliminación
de un archivo y liberación de su espacio para
re usarse.
Otras operaciones que pueden ser controladas son:
renombrar, copiar, o editar un archivo, y listar un directorio.
SISTEMAS DE PROTECCIÓN DE ACHIVOS
Los siguientes son algunos de los esquemas de protección
más utilizados por la mayoría de sistemas operativos
1.
No permitir
listar los archivos de otro usuario. De esta manera, si no se conoce le nombre
de un archivo, será muy difícil lograr el acceso ya que se tendría que recurrir
a tratar de adivinar el nombre, cosa muy poco probable.
2.
Sistema de
"passwords" o palabras de pase para cada archivo. Este sistema es
eficiente mientras se escojan los passwords al azar y se cambien frecuentemente.
La protección se puede redondear utilizando otro password para el acceso del
usuario al sistema (número de cuenta).
3.
Hacer que
el acceso al sistema sea dependiente de la identidad del usuario. Existen varias
maneras de implementar esto. Dos de las más comunes son las siguientes:
·
Asociar una lista de acceso a cada archivo y a cada
directorio, en la cual se especifican los nombres de los usuarios y tipo de
acceso que tiene cada uno de ellos a ese archivo o directorio.
De esta
manera, cuando un usuario solicita usar un
determinado archivo, el S.O. checa primero la lista de acceso de ese
archivo. Si ese usuario esta listado para ese tipo de acceso (por ejemplo escribir),
entonces le permite el acceso; si no, un mensaje de error es mostrado al usuario.
Una desventaja de este método, es que si la lista de
usuarios es grande, es tardado leer toda la lista para determinar si
el acceso es válido o no.
·
Para condensar la lista de acceso, muchos sistemas
reconocen tres clasificaciones
de usuarios:
"creador", "grupo" y "cualquier otro" (ANY).
Cada archivo tiene un creador, el usuario que lo generó.
Adicionalmente, el creador puede pertenecer a un grupo de usuarios que
están compartiendo el archivo y necesitan un acceso similar (por ejemplo los
miembros de un equipo de programadores que están desarrollando un sistema, o
los miembros de
una clase que
requieren compartir un graficador).
Finalmente todos los demás usuarios que ni crearon el archivo ni pertenecen
a ese grupo, forman la clasificación "cualquier otro".
Con esta clasificación, combinada con los tipos de acceso se puede generar
una plantilla o matriz de protección. Ejemplo:
ARCHIVO: TAREA1
ARCHIVO: GRAF
ARCHIVO: FTN
PROTECCION: R W X
PROTECCION: R W X
PROTECCION: R W X
G G A
C
C G
C
C A
El S.O. Unix utiliza el método arriba descrito. Usa
3 bits para almacenar los valores C, G, A, y otros 6 bits para almacenar el
nombre del creador y usuarios del grupo al que pertenece el archivo. Así, 9
bits son suficientes para proporcionar protección al archivo.
Los sistemas HP-3000 utilizan un esquema similar,
sólo que además de los campos R W X, existen otros como A (Append) agregar,
y S (Save) guardar.
Regresar al menú
principal 